The data is officially in, and it confirms exactly what we're experiencing: the 2026 AI Cost Crisis is entirely an architectural problem.
According to recent enterprise data, a staggering 80% of companies are blowing past their AI cost forecasts by 25% or more. Gartner even reports that worldwide AI spending is surging by 44% year-over-year.
But here's the kicker: it's not because model providers aren't lowering their baseline token rates. It's because traditional, naive agent architectures are structurally wasteful.
The context window arms race
The industry is caught in a reckless "context window arms race," blindly dumping massive 250K+ token data loads into prompts on every turn.
The result? A catastrophic phenomenon researchers are calling "context rot" — where an agent's accuracy aggressively drops the more bloated its prompt becomes, forcing the system into endless, expensive retry loops. You pay more, and the answers get worse.
As Box CEO Aaron Levie recently pointed out, token budgeting is no longer a minor engineering task — it's a C-level operational headache with no natural ceiling.
The organizations winning the margin war aren't the ones begging providers for discounts. They're the ones rewriting how context is handled.
What that architecture actually looks like
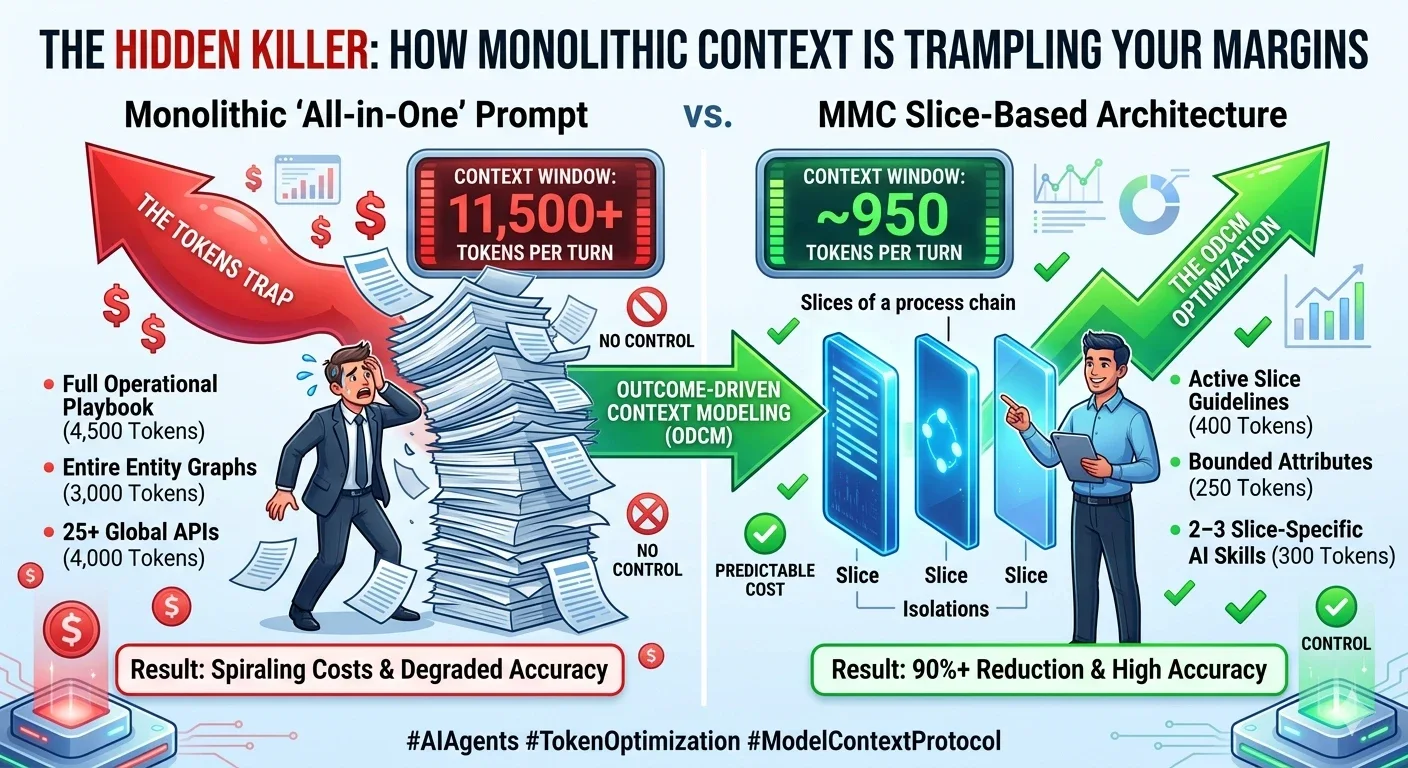
The fix is to stop shipping your entire business to the model on every call. Instead of one monolithic, "all-in-one" prompt, you decompose the work into slices — and feed the model only the atomic context a single step needs.
The difference is not incremental. Look at a single turn:
| Monolithic "all-in-one" prompt | MMC slice-based architecture | |
|---|---|---|
| Operational playbook | 4,500 tokens (full) | 400 tokens (active slice guidelines) |
| Entity data | 3,000 tokens (entire graphs) | 250 tokens (bounded attributes) |
| Tools | 4,000 tokens (25+ global APIs) | 300 tokens (2–3 slice-specific skills) |
| Context per turn | ~11,500+ | ~950 |
| Cost & accuracy | Spiraling cost, degraded accuracy | Predictable cost, high accuracy |
That's roughly a 92% reduction in tokens per turn — for the same outcome.
Why slices beat bigger windows
This is Outcome-Driven Context Modeling (ODCM): every interaction is scoped to move a process one step forward, and nothing more.
- Active slice guidelines replace the 4,500-token playbook — the agent only sees the rules for the step it's on.
- Bounded attributes replace entire entity graphs — only the fields this step touches are loaded.
- 2–3 slice-specific skills replace a 25+ API surface — the agent can't wander, so it can't get spooked into the wrong tool.
Smaller, isolated context windows don't just cost less. They're more accurate, because there's no rot for attention to drift into. Predictable cost and control are a side effect of the architecture, not a discount you negotiated.
The takeaway
The 2026 cost crisis won't be solved by waiting for cheaper tokens. It's solved by no longer wasting them. Bigger context windows are the disease, not the cure — the teams that win on margin are the ones that rewrite how context is handled, turn by turn.
At Model My Context, we build the open-source MCP infrastructure and the MMC Workbench that make slice-based, outcome-driven context the default. Explore the Workbench to see how to cut your token bill without cutting your capability.
Related reading